- Published at
Secure your Azure Databricks workloads with service identities
Using Azure Databricks Access Connectors to securely connect to other Entra ID protected services
- Authors
-
-

- Author name
- Nathan Holland
- Author LinkedIn
- Linkedin: nathanholland
Authors
-
-
Share
Table of Contents
- Introduction
- Summary
- Set up a service connector
- Example: Connecting to Azure OpenAI
- Example: Connecting to an Azure SQL endpoint
- Example: Authenticating with Azure KeyVault
- Example: Authenticating with a REST API
- Wishlist
- Helper method for connecting to Azure KeyVault
- Redaction of Secrets by Developers
- Azure Databricks KeyVault Secrets integration with service credentials
- Broader support natively in Azure Databricks
Introduction
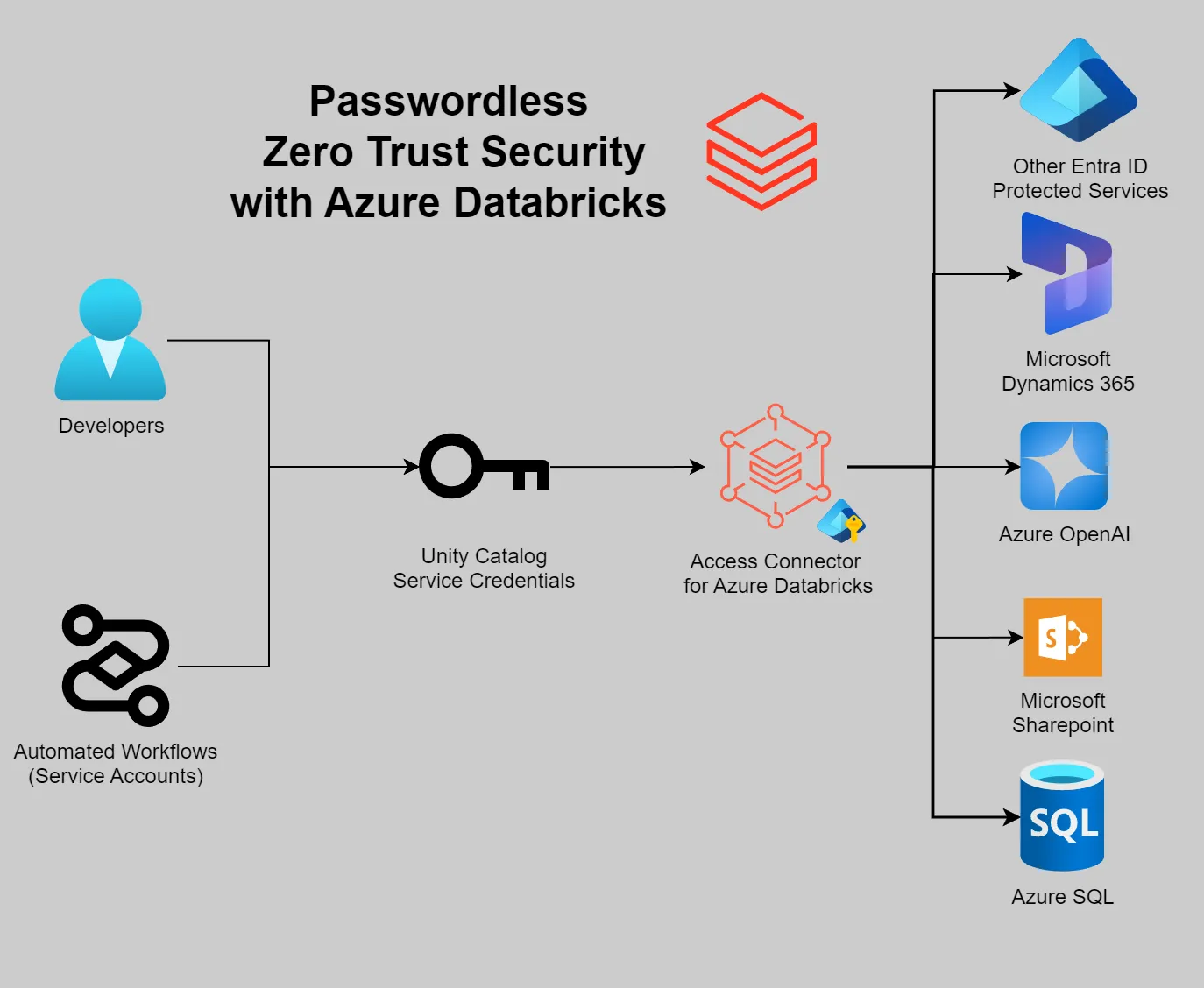
When building data pipelines you need to securely connect to other services outside of the data platform itself. Passwords or pre-shared keys are easy to setup however it can be challenging to audit who is using them if they are shared between services, or revoke access without rotation if they are leaked. This article discusses the new service credential object in Unity Catalog, which allows you to securely control access from workloads in Azure Databricks to external cloud services using Azure Entra ID.
These leverage Azure managed identities, and enable creation of short lived tokens that only the resource itself can access. Using these tokens instead of passwords removes the management overhead of rotating, sharing and deprecating old credentials. These identities integrate with nearly all services in the Microsoft ecosystem providing a more secure and streamlined way to manage access without passwords.
Summary
When using Azure Databricks, use service credentials to authenticate with Azure resources, Microsoft services and custom REST API’s secured by Entra ID. This is a great way to reduce the overhead of managing secrets and credentials and to ensure that all access is tied to an identity that can be audited and managed.
We can use them to connect to all kinds of resources, such as the examples below:
- Azure OpenAI
- Azure SQL (or an on-premises SQL Server with Entra ID Support)
- Azure KeyVault
- REST API’s Secured by Entra ID
Set up a service connector
In order to use the example code below you’ll need to first set up an service connector. You may notice this is built off the same Azure Databricks Access Connectors resource that Unity Catalog uses for storage, but are conceptually different when set up in the Unity Catalog. For the examples below I have created a service connector named sandbox-dataai-example-dbac.
Instructions on how to set up a service credential are fairly well documented, just make sure when following the first step “Configure a managed identity for Unity Catalog” when you follow the instructions on the linked page you stop at “Step 1”. The later steps are only required when configuring an access connector for access to a storage account.
It may help when following along with the examples to have familiarity with the Azure Portal and how to configure role based access control (RBAC) and understand the fundamentals of Managed identities in Entra ID.
Example: Connecting to Azure OpenAI
We’re going to assume we’ve already configured a new Azure OpenAI resource in the portal and created a deployment (in our example gpt-4o-mini).
Following the quick start guides you may be familiar with the environment variable AZURE_OPENAI_API_KEY or the api_key argument in the OpenAI library. Instead of these we’ll be using the managed identity we created above to authenticate with Azure OpenAI by going to the Azure OpenAI resource and providing the RBAC Role Cognitive Services OpenAI User role to our service credential.
You can see in the documentation the OpenAI library can take a token directly using azure_ad_token, or through a provider azure_ad_token_provider that takes a function that returns a token. The provider will work better for longer running processes that use the client for a long time.
import os
from openai import AzureOpenAI
from azure.identity import get_bearer_token_provider
# Replace with your OpenAI endpoint
openai_endpoint = "https://sandbox-dataai-oai.openai.azure.com/"
deployment_name = "gpt-4o-mini"
credential = dbutils.credentials.getServiceCredentialsProvider('sandbox-dataai-example-dbac')
client = AzureOpenAI(
azure_endpoint = "https://sandbox-dataai-oai.openai.azure.com/",
azure_ad_token_provider= get_bearer_token_provider(credential, "https://cognitiveservices.azure.com/.default")
api_version="2024-02-01"
)
response = client.chat.completions.create(
model=deployment_name,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI work with Azure Databricks?"}
]
)
print(response.choices[0].message.content)If you’re not using the Databricks Runtime for Machine Learning you’ll need to install the Azure Identity and OpenAI libraries by running the following in a new cell
%pip install openai azure-identityExample: Connecting to an Azure SQL endpoint
We can’t use Lakehouse federation for this yet but it’s in my wishlist for something I’d love to see.
We’ll first need a sample database to work with, and once it is deployed we can set up the permissions for the service account by running a SQL script against the database as an administrator. In this case we’ll be using the SalesLT.Customer table in the sandbox-dataai-adventureworksdb database.
-- Create a database user for the service account
CREATE USER [sandbox-dataai-example-dbac] FROM EXTERNAL PROVIDER;
GO
USE [sandbox-dataai-adventureworksdb];
GO
GRANT SELECT ON SalesLT.Customer TO [sandbox-dataai-example-dbac];
GOWith the permissions configured - we can now load a table into a Spark Dataframe.
driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
credential = dbutils.credentials.getServiceCredentialsProvider('sandbox-dataai-example-dbac')
database_host = "sandbox-dataai-mssql.database.windows.net"
database_port = "1433"
database_name = "sandbox-dataai-adventureworksdb"
table = "SalesLT.Customer"
accessToken = credential.get_token("https://database.windows.net/.default").token
url = f"jdbc:sqlserver://{database_host}:{database_port};database={database_name}"
remote_table_df = (spark.read
.format("jdbc")
.option("driver", driver)
.option("url", url)
.option("dbtable", table)
.option("accessToken", accessToken)
.load()
)
remote_table.display()Example: Authenticating with Azure KeyVault
For Azure KeyVault we’ll assign our service account access, we can refer to the documentation for how to do this. For simplicity we’ll be assigning the Key Vault Secrets User or Key Vault Secrets Officer role and create a ‘test’ secret in the Azure KeyVault for this example to retrieve.
# You'll need to install the azure-keyvault-secrets library using %pip install azure-keyvault-secrets
from azure.keyvault.secrets import SecretClient
credential = dbutils.credentials.getServiceCredentialsProvider('sandbox-dataai-example-dbac')
vault_url = "https://sandbox-dataai-example-kv.vault.azure.net/"
client = SecretClient(vault_url=vault_url, credential=credential)
print(client.get_secret("test").value)Example: Authenticating with a REST API
We’ll be replicating the previous example, but using the KeyVault REST API and supplying a access token to authenticate.
As a bonus I thought I might see if I could redact the returned secret similar to the dbutils.secrets.get() method so in the logs and notebook output it will show [REDACTED]. I’ve noticed the CredentialRedactor class defined in the Spark configuration, and by using Py4j bindings we can call this method to redact the secret.
Redaction in this way is definitely not supported in production (any Python method starting with an underscore is a red-flag for production code), but it would be nice to have a supported way to do this in the future!
import requests
def get_keyvault_secret(vault_name_or_url, secret_name, credentials_provider_name =None, version=None ):
credential = dbutils.credentials.getServiceCredentialsProvider(credentials_provider_name)
# We create a new header here that passes the bearer token to the service - this is a standard practice for all Entra ID secured REST APIs.
headers = { "Authorization": f"Bearer {credential.get_token("https://vault.azure.net/.default").token}" }
if(not vault_name_or_url.startswith("http")):
vault_url = f"https://{vault_name_or_url}.vault.azure.net/"
else:
vault_url = vault_name_or_url
response = requests.get(f"{vault_url}secrets/{secret_name}?api-version=7.4", headers=headers)
# In production you'd check the API documentation to handle errors and retries - for example with KeyVault, 404's can mean the secret doesn't exist, 429's mean you're hitting the service too much.
response.raise_for_status()
sc._jvm.com.databricks.logging.secrets.CredentialRedactor.addSecret(response.json()['value'])
return response.json()
get_keyvault_secret("sandbox-dataai-example-kv", "test", 'sandbox-dataai-example-dbac')Wishlist
Service credentials are great addition to the Azure Databricks platform, one I’ve looked forward to for some time. However I have a few items on my wishlist on how this could be improved further - in ascending order of complexity.
-
Helper method for connecting to Azure KeyVault
As an easy win, it would be nice to have built in helper method for this rather than having to roll our own, I’d suggest something that could easily be called like the example above.
dbutils.secrets.getKeyVaultSecret(url, secretName) -
Redaction of Secrets by Developers
It would be nice to expose a way to add custom secrets to be redacted in the logs (as a best effort) - as far as I can tell messing directly with the CredentialRedactor isn’t fully supported - and I can think of a few cases where it would be nice to mask what goes into the logs.
This could be as easy as exposing the CredentialRedactor in Python officially - perhaps something like
dbutils.logging.addSecretRedaction()that uses the credential redactor implementation defined in the spark configuration. -
Azure Databricks KeyVault Secrets integration with service credentials
I quite like the simplicity of the
dbutils.secretslibrary and I’d suggest that the current method of backing secrets with Azure KeyVault through the magic string could be updated so it can support being linked by anybody who has sufficient permissions to the service credential.This is a much better user experience than needing to know both the URL of the secret store AND the name of the credential that can access it and would provide an easier and more secure way of registering KeyVault without requiring Owner/Contributor access to the KeyVault in order to set it up.
-
Broader support natively in Azure Databricks
Support for service identities in more use-cases such as in Unity Catalog managed HTTP Connections, Mosaic Endpoints, and Lakehouse Federation would be a great addition. This would allow for a more secure and streamlined way to connect to services without needing to create application registrations and deal with OAuth2 secrets.